|
Programming a Virtual File System - Part II by (22 August 2001) |
Return to The Archives |
Introduction
 |
| First, I want to say "thank you" for your great feedback. I received about 50 e-mails containing lots of helpful hints, comments, criticisms and ideas. I also want to express a special thank you to John Rush, the guy who not only gave me lot of ideas, but who also implemented half of the filter system and showed me how to use Structured Storage. Thanks. |
|
Winds Of Change
|
|
Because of your great comments, the interface of the VFS has changed enormously.
So the first subpart of this tutorial will be to show you all the interface
changes. The second part will be to introduce you to the real implementation of
the VFS. I will show two possible implementations for the VFS, one more and one
less platform independent. For those of you that actually want CODE now *hehe*, I've added the code of my old VFS here (which is less well-structured than the VFS, but still worth checking out). Before we dive into the parts of VFS that have changed, have a look at the header file. |
|
Major Changes
|
One major change, is that the the interface is now completely platform independent.
To achieve this it uses an ANSI C++ compliant header file for the interface
and a separate header file for any
data types that are needed. This is a common
approach to platform-independence and is used by OpenGL, among others. The data
types area defined in VFS_TYPES.H and are prefixed with VFS_ so as to be easily
recognizable. This file may need to be modified for use on your platform. VFS_LONGLONG
for example is defined as __int64 which is Microsoft specific. You will need
to replace that with an appropriate 64-bit integer for your platform.
Additionally, I changed the error handling behavior to use an enumeration VFS_ErrorCode
which contains all possible error codes. I'll probably add more error codes
to this enumeration in the future. Notice that the error code isn't directly
returned by the functions, but through the VFS_GetLastError() function. Here's
a small table containing the error return values for the return value types:
This means if a function VFS_DWORD VFS_GetNumFilters() returns VFS_ERROR, this indicates an error. The error code and a string containing the description of the error code can be retrieved like this:
So this is pretty easy stuff. The last change I made (which you'll probably have noticed), is that I am now using Unicode. Core components such as this are intended to be used throughout the world. To best support this, all the interfaces are now exclusively Unicode. This will also allow maximum file-naming flexibility without breaking file-format compatibility between different locals. Although many Win9x users may not be aware of it, many file systems already support Unicode filenames. Your code should not have to change much, though. You only have to use the VFS_TEXT macro for your hard-coded strings and use some |
|
Filter System Changes
|
|
According to a suggestion by John Rush, I changed the Filter Structure to a
class and added two member functions LoadData() and SaveData() to the
VFS_Filter, allowing the filter to store filter-dependent settings (one setting
entry per archive!!!). So, a Filter can store a compression table, encryption
keys, etc. in the archive and load that if it needs to do so. These two
functions need not be implemented by every Filter -- the base class provides
stubbed functionality so just don't override them unless you need this feature. The filter's LoadData() method is called whenever an Archive is loaded, and the SaveData() is called when an archive is created or closed. Another interesting change is that I don't use LPCBYTE pointers anymore for the filter callback functions, but Reader/Writer function callbacks. This is better since the Filters don't need to allocate memory anymore, they just stream from/into the file. Here's the up-to-date version of my ONEADD filter called MULTIADD, which now uses the SaveData/LoadData functions (and which is still as useful as in the last issue ;-):
You just have to register the filter using VFS_Register( &g_MultiAddFilter ) before opening any Archive and that's it ;-) Neat, isn't it ??? |
|
Streaming
|
| For the streaming stuff some of you guys mentioned: My implementation of the VFS will only load the entire file into memory if any filters are applied to a file. Otherwise it will stream per default, so we don't need any special streaming functions. |
|
Feeling Safe
|
I changed some #define-itions to enumerations (just for type safety). For the same reason, I'm using
now instead of
|
|
The Utility Interface
|
In the Utility Interface you can now find these functions:
These are small utility functions used to split a file name into its component parts. Consider the path name "Textures/Sarge/AlphaTex.bmp". The following table shows the return values (i.e. the value pszPath/pszName/pszExtension contains after the function call) for each of the utility functions:
So, that's it for the interface changes. There are many more small changes that you'll notice when looking at the header. But these are easily recognizable and not important enough to be covered here. This section of the Tutorial is fairly important, so please tell me if I made any mistakes or if you want to show me any additional implementation possibilities (that make sense ;-) or if you have ideas on improving the implementation. |
|
Implementing the VFS - Approach 1
|
|
The first approach, let's call it VFS1, is the approach I
used when I created my old VFS (you can download this
badly-structured, but (I think) well-commented piece of code here). In VFS1, archive files have the following layout:
The Header has the following structure:
The Filter Structure has the following structure:
The Dir Structure has the following structure:
The File Structure has the following structure.
So what do you think about this structure? It seems relatively reasonable to me ;-) But it has the following disadvantages: - Archive Manipulation Speed: The Archive Manipulation Speed is very slow. We'd better use some kind of cluster algorithm (like the one approach 2 uses). And, of course, since VFS1 (Approach 1) is a platform-independent approach (and so the implementation will be), we've the next disadvantages: - Lack of speed & Memory consumption: If you wanted to implement VFS1 totally platform-independent, you can't use file-mapping and so on. You could though, if you only want to hold the archive format platform-compatible. And of course here are the advantages: - Easy file format. - Platform compatible. |
|
Implementing the VFS - Approach 2
|
|
The second approach, is not platform-independent at all. It uses Microsoft's
Structured Storage API. Here's a short overview about Microsoft's Structured
Storage (extracted from the Platform SDK February 2001 Edition): "...Structured Storage provides file and data persistence in COM by treating a single file as a structured collection of objects known as storages and streams. The purpose of Structured Storage is to reduce the performance penalties and overhead associated with storing separate objects in a single file. Structured Storage provides a solution by defining how to treat a single file entity as a structured collection of two types of objects � storages and streams � through a standard implementation called Compound Files. This lets the user interact with and manage a compound file as if it were a single file rather than a nested hierarchy of separate objects..." and "...Traditional file systems face challenges when they try to store efficiently multiple kinds of objects in one document. COM provides a solution: a file system within a file. COM structured storage defines how to treat a single file entity as a structured collection of two types of objects � storages and streams � that act like directories and files. This scheme is called structured storage. The purpose of structured storage is to reduce the performance penalties and overhead associated with storing separate objects in a flat file...." Benefits mentioned by the Platform SDK Documentation (and I agree to the Platform SDK ;-) are:
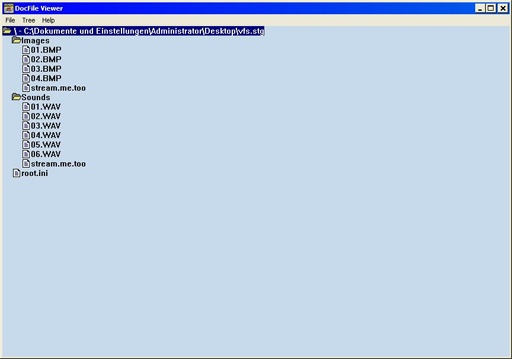 You see the hierarchical structure ;-)? And did you notice that Microsoft Word uses DocFiles, too? Another benefit of using Structured Storage is simply that we don't have to write all the code by ourselves, but that we can simply use the highly-optimized Microsoft Structured Storage API. The filters and their configuration data could be stored in a separate subfile like "settings.ini" in the archive file and every file in the filter will have one DWORD bitset or something like this at the beginning. This bitset which indicates which filters are used, won't be accessible using the VFS_File_Read()/VFS_File_Write() functions, it simply doesn't "exist" for the outer world ;-) So, we all agree that the DocFile File Format is good, but the major disadvantage is that it's absolutely not platform-compatible. That's bad. Really bad. |
|
The Microsoft DocFile Format
|
| Luckily, there is a library called "libole" for Linux which contains functions to access DocFiles. So the Linux implementation of the VFS could use "libole" to implement the archive functions. |
|
Other Implementation Details
|
|
If we're going to use VFS2, we'll use the Microsoft concept of streams, since
IStreams and IStorages are the basic blocks of Structured Storage. For these who
don't know streams very well, here's a little extract from the Platform SDK
Documentation: "The IStream interface lets you read and write data to stream objects. Stream objects contain the data in a structured storage object, where storages provide the structure. Simple data can be written directly to a stream but, most frequently, streams are elements nested within a storage object. They are similar to standard files." Streams have similar methods to the Standard Library's fopen()/fclose()/fseek()/f... functions, for instance the IStream's Seek() function acts like fseek(). The advantage of the IStream concept is IStreams are applicable for both Compound Files and Standard Files. So once we've created a IStream interface, we don't have to care about the file type anymore, we can just use the IStream methods. |
|
Which Approach Are We Going To Use???
|
| My personal favorite is using Structured Storage (VFS2, the 2nd approach), simply because it saves me a lot of work ;-) To be serious, I like using the Structured Storage for other reasons: Since Microsoft's programmers are usually good and the Structured Storage API is supposed to be highly optimized for Win32, it'll be much faster using Structured Storage instead of writing our own Archive management classes for the general case. But I'd like to hear your opinion on this point. What do you think? Just tell me what you think and vote for your favorite. Thanks ;-) |
|
Conclusion
|
|
I hope this article wasn't too boring for you. I covered a lot of stuff - the
new interface and how the implementation is going to work. Another idea that came into my mind (I don't think mentioned it in the last issue, did I?) is to create a WinZip-like tool for managing Archive Files. What do you think? It would simplify archive management a lot, show you how to use the VFS and, of course, it would also be cool to show your friends, "Hey guys, wanna try my WinZip???" ;-) I wish you the best for your nightly coding sessions, Michael You can grab all sources for this issue here. |
|
Article Series:
|